Oi, meu nome é Denise Merazzi
Eu sou Cientista de Dados
Através desse portfólio, você pode me conhecer melhor e conhecer os projetos que estou trabalhando, para adquirir experiência na área. Aqui, apresento os resultados dos projetos e ferramentas que utilizei nesse processo.
Me contrate
Sobre Mim
Eu me chamo Denise Merazzi e sou Cientista de dados
Sou uma profissional experiente na área de Pesquisa e Educação que, atualmente, estou em
transição para atuar profissionalmente como Cientista de Dados.
Como pesquisadora, construí a minha trajetória na área Acadêmica, onde tive a oportunidade
de aprender com pesquisadores sêniors e entender o funcionamento de projetos desde a
coleta de dados, tratamentos estatísticos e publicação de resultados.
Na Academia, para desenvolver os projetos de pesquisa, utilizei pequenos conjuntos de dados,
gerando resultados muito específicos, que serviam para explicar fenômenos específicos e
locais. Isso foi o que me fascinou, quando escolhi migrar para a área de Ciência de Dados:
trabalhar com grandes conjuntos de Dados, com ferramentas de programação, estatística e
Inteligência Artificial, trazendo resultados que podem, além de explicar fenômenos, propor
modelos que possam ser generalizados.
Aniversário : 14 jul 1980
Idade : 42
Website : denise.merazzi.com.br
Email : [email protected]
Graduação : Química
Phone : (51) 99354-6727
Cidade : Canoas - RS
Freelance : Disponível
Uso de Modelos Machine Learning
Análise de Dados com SQL
Python
Visualização com Streamlit
Education
2022 – atual
Trilha para formação: Cientista de Dados
Comunidade DS
2022 – 2024
Trilha para formação: Cientista de Dados
Data Science Academy (DSA)
2021
Bootcamp – Trilha de Ciência de Dados
Núcleo de Estudos em Inteligência, Gestão e Tecnologias para Inovação (IGTI)
2007 - 2008
Mestrado em ensino de Ciências e Matemática
Universidade Luterana do Brasil
2002 – 2006
Graduação em Química
Universidade Luterana do Brasil
Experience
2022 - atual
Cientista de Dados
Construção de projetos, desde a concepção até a publicação de algoritmos de Machine Learning, realizados a partir da análise de dados públicos, visando resolver problemas de negócio, utilizando conceitos e ferramentas da Ciência de Dados, como Linguagem Python, R, SQL e bibliotecas (análise estatística, Machine Learning e visualização de dados).
2003 – 2021
Professora e pesquisadora
Trabalho desenvolvido na Universidade, durante a Graduação e Mestrado, junto ao
Laboratório de Pesquisa em Ciências. Esta experiência me proporcionou a vivência
em todas as etapas de desenvolvimento de projetos de pesquisa: coleta e análise de
dados, escrita e publicação de artigos científicos, participação e organização de
eventos acadêmicos, aprimorando as minhas habilidades de pesquisa junto aos
pesquisadores seniors.
Atuação em escolas públicas e privadas, lecionando para estudantes de Nível
Fundamental e Médio. Desenvolvimento de projetos de Iniciação Científica e
preparação para o ENEM e Vestibulares.
2002 – 2003
Análises físico-químicas – Laboratório de Controle de Qualidade
Análises físico-químicas e microbiológicas de produtos farmacêuticos.
Habilidades e Competências
Estatística
Preparação e análise exploratória e estatística de dados, utilizando as linguagens Python, R e SQL e bibliotecas como NumPy, Pandas, MatPlotLib, SciPy, Math, Seaborn, entre outras.
Inteligência Artificial
Construção de Modelos de Machine Learning através de algoritmos de aprendizagem supervisionada e não supervisionada.
Negócios
Soluções de problemas de negócio através de insights partindo de testes de hipóteses e construção de modelos capazes de trazer soluções de classificação, regressão e clusterização.
Dashboards
Construção de Dashboards com as ferramentas StreamLit e Power BI.
Data Exploration
Análise exploratória de dados e levantamento de informações, construindo relatórios rápidos e específicos, utilizando consultas em SQL e Excel.
Portfolio
Meus últimos projetos :
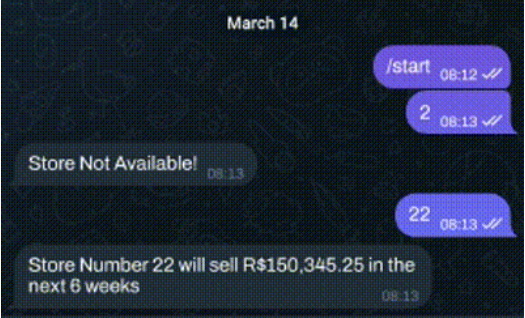
Sales Prediction - Rossmann
Regressão
A construção desse projeto atendeu ao método CRISP de desenvolvimento de projeto, passando por todas as etapas do ciclo de um projeto de Ciência de Dados do início ao fim.
Iniciou-se com a coleta, limpeza, feature engineering e preparação dos dados.
Partindo para a modelagem dos dados, com o treino, teste e avaliação dos modelos de Machine Learning.
Finalizando com o deploy do modelo em produção e disponibilizando as previsões para o CEO na web, atráves do Bot Telegram.
O projeto tem como objetivo, realizar a previsão de vendas das próximas 6 semanas de todas as lojas da rede de farmácias Rossmann.
Foi construído junto à Comunidade DS, na trilha de estudos para Data Science.
Ferramentas utilizadas
- Linguagem Python
- Flask
- SkLearn
- Boruta
- Scipy
- MatplotLib
Health Insurance Cross Sell
Classificação – Learn to rank (MLR)
O projeto teve como objetivo construir uma lista de classificação ordenada dos 20.000 clientes mais propensos a adquirir o novo produto (seguro de veículos), partindo dos clientes que já utilizavam o seguro-saúde.
Ferramentas utilizadas
- Linguagem Python
- Flask
- SkLearn
- Boruta
- Scipy
- MatplotLib
Heart Desease Prediction
Classificação
o objetivo do projeto foi construir um modelo capaz de detectar com maior precisão a identificação de doenças cardíacas.
Ferramentas utilizadas
- Linguagem Python
- Flask
- SkLearn
- Boruta
- Scipy
- MatplotLib

Segmentação de clientes com base em análise RFV
Clustering
Projeto construído junto à Data Science Academy, na trilha de estudos de Data Science.
O objetivo do projeto é analisar o comportamento dos clientes (ter uma visão completa dos clientes), através da análise RFV, que segmenta os clientes a partir das características:
- Recência: Medida de tempo, ou seja, quando foi a última compra do cliente
- Frequência: Qual a frequência de compras em um determinado período de tempo;
- Valor Monetário: Valor total da compra.
A partir dessa análise é possível prever o comportamento dos clientes e possivelmente aumentar o ciclo de vida deles dentro do negócio, ganhando consumidores cada vez mais fiéis à marca.
Ferramentas utilizadas
- Linguagem R
- Aprendizagem não supervisionada Kmeans: segmentação de clientes (clusterização)

Como o PIB e a Desigualdade Social Influenciam no Crescimento da Netflix?
Clustering
Projeto construído junto à Data Science Academy, na trilha de formação para Cientista de Dados, utilizando a Analytics Web App (shiyApp) para grandes volumes de dados.
O objetivo do projeto é investigar, através da análise de dados, se a renda das pessoas que utilizam o Netflix influencia na rentabilidade dessa Empresa.
Ferramentas utilizadas
- Linguagem R: Limpeza, preparação, análise estatística dos dados.
- Pacotes Shiny, plotly e shinythemes: construção de um Dashborad analítico.
Data Science no Varejo com Market Basket Analysis (MBA)
Clustering
Projeto construído na Formação para Cientista de Dados, junto à Data Science Academy.
O objetivo do projeto é resolver um problema de negócio que busca padrões de compras, através da técnica conhecida como Market Basket Analysis (MBA).
Ferramentas utilizadas
- Linguagem R: Limpeza, preparação e análise estatística de dados.
- Algoritmo Apriori: buscou os padrões através de três métricas: support (a fração de transação de um produto no total de compras), Confidence (a probabilidade do item x e o item y serem comprados juntos) e Lift (indicador de aumento da confiança).

Insights para plataforma digital: House Rocket
Insights
Projeto realizado junto à Comunidade DS:
Identificação dos imóveis em melhores condições e melhor preço para compra, possibilitando a oportunidade de maior rentabilidade nas transações de venda.
A análise foi realizada em linguagem Python e o resultado foi a construção de duas tabelas:
- recomendação de compra
- venda e variação de preço regional x sazonalidade.
O projeto foi construído com a finalidade de gerar insights para uma plataforma digital de vendas de imóveis, visando encontrar as melhores oportunidades de compra e venda de imóveis, sugerindo o preço de venda e maximizando a receita.
Ferramentas utilizadas
- Linguagem Python
- PyCharm
- Plotly
- Matplotlib
- Seaborn

Insights para aluguéis de imóveis: AirBnb
Insights
Projeto realizado junto à Comunidade DS:
Através da análise de dados, foi possível encontrar os imóveis com a melhor oportunidade de negócio, sendo alugados rapidamente, em boa localização e preço, visando a melhor rentabilidade e retorno do valor investido.
O resultado foi disponibilizado através de relatórios que possibilitaram a identificação das melhores oportunidades de negócios, além de um mapa interativo por região.
Ferramentas utilizadas
- Linguagem Python
- Plotly
- Matplotlib
- Seaborn

Insights para um Marketplace: Fome Zero
Insights
Projeto realizado junto à Comunidade DS:
Construção de um Dashboard interativo com a ferramenta Streamlit e uso da linguagem Python para análise de dados e geração de insights, disponibilizado ao time de negócios de um Marketplace de restaurantes, contribuindo na tomada de decisões mais assertivas e estratégicas
Ferramentas utilizadas
- Linguagem Python
- Streamlit
- Plotly
Relatórios Olist
Treinamento para consultas em SQL
O objetivo do projeto foi gerar diversos relatórios contendo informações relevantes, para uma startup que oferece um serviço facilitador para o cadastro de produtos de e-commerce, de forma rápida, através de querys em SQL, com a finalidade de demonstrar os cenários que abrangem todo o negócio: lojas, vendedores, entregas e produtos.
Ferramentas utilizadas
- Linguagem SQL
- DBEaver
- SQLite