Nesse post você vai encontrar técnicas para fazer as transformações necessárias nas variáveis, com a finalidade de ganhar performance no modelo.
O aprendizado dos algoritmos de Machine Learning é baseado em diversas premissas, ou seja, detalhes que facilitam a aprendizagem e influenciam a performance do modelo.
Essas premissas seguem a base da teoria da Navalha de Ockhan, em que o conjunto de dados mais adequado para o modelo, deve estar construído com simplicidade e estar organizado de forma sistemática, apresentando:
- A menor dimensionalidade
- A menor complexidade
- Menor nº de colunas
É importante destacar que é mais fácil o algoritmo aprender com dados numéricos e na mesma escala, porque os métodos de otimização que estes modelos utilizam tem a sua base em cálculos, como as derivadas e a soma.
O primeiro passo para obter um conjunto de dados adequado às premissas que atendem à boa performance do modelo, está em fazer uma boa análise exploratória univariada, bivariada e multivariada. Pois, dessa forma, é possível encontrar quais variáveis são importantes e quais estão correlacionadas, podendo ser agrupadas ou excluídas, para a melhor generalização do modelo.
Existem vários algoritmos que ajudam nesse seleção de features, mas é importante que o Cientista de dados faça a sua análise exploratória antes dessa etapa, para adquirir conhecimento a fim de confirmar ou confrontar as features que o algoritmo apresenta como sendo as mais relevantes.
É necessário que os dados estejam em uma mesma escala para que a comparação dos resultados não seja enviesada ou equivocada. Para isso, são utilizadas três técnicas que quando aplicadas, fazem com que o conjunto de dados continue no mesmo shape (nº de linhas e colunas) e no mesmo range (escala).
Abaixo descrevo estas técnicas de preparação de dados separadamente. São elas: Normalização, Rescaling e Transformação (Encoding e Natureza).
NORMALIZAÇÃO
É comum encontrarmos em um Dataset, dados que estejam organizados em colunas com um range muito diferente, o que torna a comparação dos dados muito “injusta”. Quando temos esse cenário é necessário equalizar a importância das features, para que o modelo entenda que não necessariamente a feature que tem o range maior é a mais importante.
Este tipo de preparação desloca a variável para um mesmo range (mesmo conteúdo, mesma escala). Através deste método ocorre a reescala do centro para o zero com desvio padrão igual a 1.
A fórmula que aplicada para realizar esta reescala é:
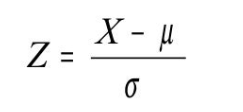
Sendo: Nova_coluna = coluna – média / desvio-padrão
No entanto, este método possui algumas limitações e só pode ser aplicado em dados que apresentam uma Distribuição Normal/Gaussiana.
RESCALING
É um método que reescala os dados para o intervalo entre zero e 1. Sua utilização é recomendada quando os dados apresentam um comportamento não Gaussiano, ou seja, não apresentam uma Distribuição Normal.
É importante observar se a coluna possui outliers, porque isso influencia na escolha do método de Rescaling. Se não houver outliers, pode ser utilizada a técnica MinMaxScaler, que considera valores mínimo e máximo. E, se houver outliers, utiliza-se uma técnica mais robusta diante de outliers, que é a RobustScaler. Essa técnica se comporta melhor com outliers porque, diferente da Normalização que utiliza a Média e o MinMaxScaler que utiliza os valores mínimo e máximo, a RobustScaler utiliza os quartis.
Fórmulas:
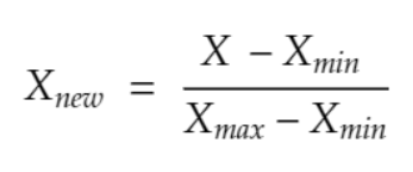
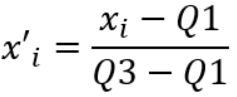
O MinMaxScaler e RobustScaler são classes encontrados no pacote Sklearn:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# Import from Sklearn.preprocessing import RobustScaler, MinMaxScaler # Método utilizado para conjuntos de dados sem outliers mms = MinMaxScaler() ## Intancia df['coluna'] = mms.fit_transform( df[['coluna']].values ) # Método utilizado para conjuntos de dados com outliers rs = RobustScaler() ## Instancia df['coluna'] = rs.fit_transform( df[['coluna']].values ) ## Nota: # fit_transform é um método que encontra os parâmetros da fórmula e aplica nos dados. Os parâmetros são os quartis 1 e 3. |
TRANSFORMAÇÃO
Aqui vamos abordar dois tipos de transformações: Encoding (transformar dados categóricos em numéricos) e Transformação de Natureza.
Encoding
Existem muitos tipos de transformação de dados categóricos em numéricos. Escolher qual Encoding usar, não é uma tarefa fácil, por isso é tão importante conhecer o conjunto de dados através da análise exploratória e também, fazer testes, calculando o erro, para descobrir qual forma é a mais adequada de tratar esse conjunto de dados.
Abaixo, segue um breve resumo de técnicas de Encoding, que são usadas para “traduzir” categorias em números:
a) One Hot Encoding
É uma técnica bem simples de ser compreendida. Observe que no exemplo abaixo, as cores são substituídas pelos números 1 e 0. Se for verdadeiro é 1 e se for falso é 0.
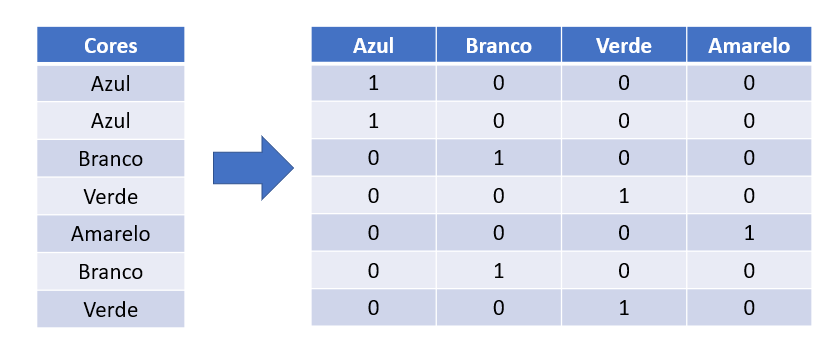
É interessante usar para variáveis categóricas que dão a ideia de estado (Ex: feriado, temperatura).
- Vantagem: Super simples de aplicar.
- Desvantagem: cria novas colunas no dataset e aumenta a dimensionalidade (overfitt).
b) Label Encoding
Esta técnica substitui a categoria por números de forma aleatória. Observe que no exemplo abaixo, as cores são substituídas por números.
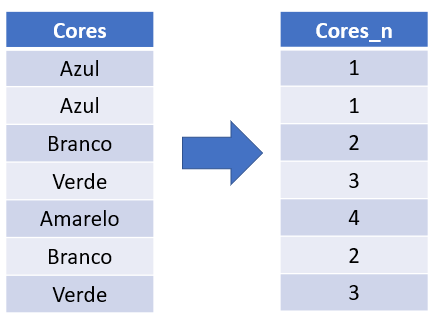
Isso funciona muito bem para variáveis que são apenas nomes (ex: nome de lojas).
c) Ordinal Encoding
É uma técnica parecida com Label Encoding, porém tem uma diferença: respeita uma relação de ordem (hierarquia). Observe que no exemplo abaixo, a hierarquia é de tamanho: menor ao maior:
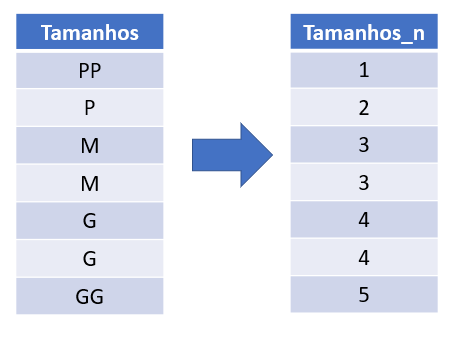
Funciona muito bem quando tem uma relação de maior e menor (ordem). Exemplo: baixo, médio, alto / muito frio, frio, morno, quente, muito quente.
d) Target Encoding
Leva em consideração a variável resposta (target). Por exemplo, calcula a média de vendas para cada um dos níveis das categorias (cores, cidades).
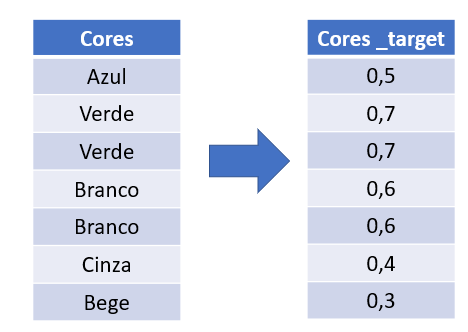
Funciona bem quando tem muitos níveis de categorias. Exemplo: cores.
e) Frequency Encoding
É parecido com Target Encoding. Faz uma contagem da frequência e calcula média (em percentual).
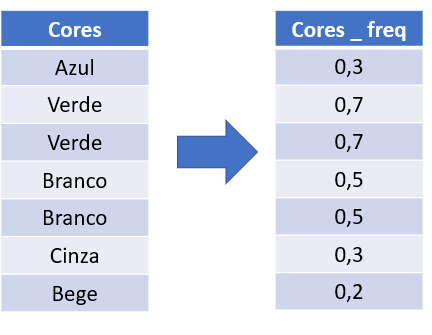
f) Embedding Encoding
É um método implícito dentro das redes neurais profundas (deep learning). São camadas que traduzem a variável categórica para numérica tentando manter uma relação de distância dentro de um contexto. É muito utilizado dentro de NLP e previsão de demandas.
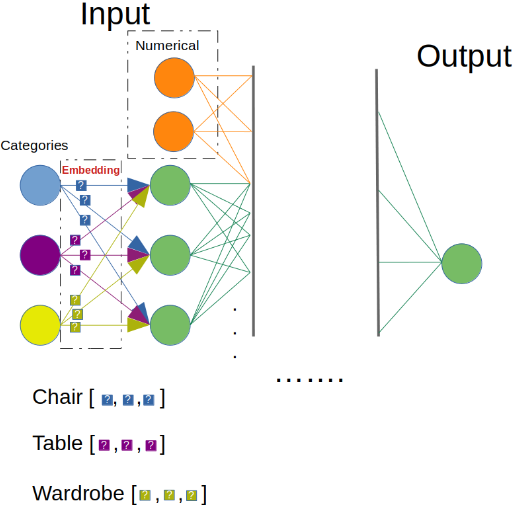
g) Exemplo de implementação do código de alguns Encodings:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# Import from sklearn.preprocessing import LabelEncoder # Instancia: le = LabelEncoder() # One Hot Encoding: df = pd.get_dummies(df, prefix=['Feriados'], columns=['Feriados']) # Label Encoding: df['tipo_comida'] = le.fit_transform(df['tipo_comida']) # Ordinal Encoding: tamanho_dict = {'pequeno':1, 'medio':2, 'grande':3} df['tamanho'] = df['tamanho'].map(tamanho_dict) |
transformação
Existem dois principais tipos de transformações: Grandeza e Natureza.
a) Transformação de Grandeza: o objetivo é trazer a variável resposta com uma distribuição mais próxima da normal. Os algoritmos de ML tem a premissa que os dados sejam normalmente distribuídos, isso aumenta a acurácia do modelo.
b) Transformação de Natureza: o objetivo é trazer a natureza real dos dados. Por exemplo, se a natureza é cíclica os dados devem apresentar a forma de ciclo. Os meses são um bom exemplo, porque quando colocados em números de 1 a 12 – janeiro é perto de fevereiro mas é longe de dezembro, mas se isso for pensado em número (por exemplo janeiro de 2021 é perto de dezembro de 2020), perde-se essa noção de cíclico. Precisamos deixar janeiro próximo de dezembro.
Tipos de transformação de grandeza
a) Transformação Logarítmica: transforma um conjunto que tenha uma skill para a direita ou esquerda mais para o centro, mais próxima de uma normal. Aplica o log em todas as variáveis resposta.
b) Transformação Box-Cox: Também aproxima o conjunto de dados de uma normal. Tem uma fórmula e também aplica o log em todas as variáveis resposta.
c) Transformação Cube-Root: Extrai a raiz cúbica de todos os valores.
d) Tranformação Square-Root: Extrai a raiz quadrada de todos os valores.
e) Transformação Seno e Cosseno: Aplica o seno e o cosseno em todos os valores.
f) Exemplos de implementação de código:
|
1 2 3 4 5 |
# Import: import numpy as np # Transformação Logarítmica df['variavel_resposta'] = np.log1p(df['variavel_resposta']) |
transformação de natureza cíclica
Calcula-se o seno e cosseno, que combinados vão representar a natureza cíclica. Na prática, aumenta a dimensionalidade do dataset, porque cria novas colunas. Apesar disso, melhora a performance porque a natureza da variável fica equalizada.
Exemplo de implementação de código:
|
1 2 3 4 5 6 7 8 9 |
$ import numpy as np # Dias do mês df['dia_sin'] = df['dia'].apply(lambda x: np.sin(x*(2. *np.pi/30))) df['dia_cos'] = df['dia'].apply(lambda x: np.cos(x*(2. *np.pi/30))) # Meses do ano df['mes_sin'] = df['mes'].apply(lambda x: np.sin(x*(2. *np.pi/12))) df['mes_cos'] = df['mes'].apply(lambda x: np.cos(x*(2. *np.pi/12))) |
Concluindo este tema, observamos que são muitas as formas de realizar o encoding das variáveis e, que estas são técnicas necessárias e amplamente utilizadas antes de fazer o treinamento do modelo de Machine Learning.
Agradeço seu tempo de leitura. Fica como dica a leitura abaixo, para aprofundar o tema.
All about Categorical Variable Encoding | by Baijayanta Roy | Towards Data Science
Category Encoders — Category Encoders 2.6.0 documentation (scikit-learn.org)
Navalha de Ockham – Wikipédia, a enciclopédia livre (wikipedia.org)
Meus contatos:
github.com/denisemerazzi
www.linkedin.com/in/denisewmerazzi/