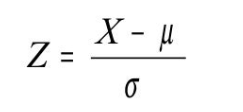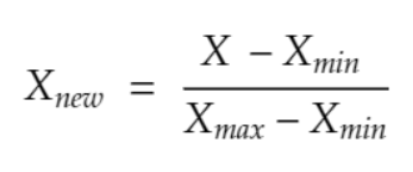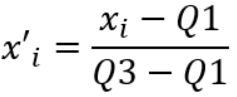Nesse post, você vai conhecer algumas técnicas para escolher quais são as variáveis relevantes dentro do conjunto de dados e usá-las para o treinamento do algoritmo de Machine Learning e quais variáveis são colineares, para eliminá-las.
“Usamos a seleção de atributos para selecionar aqueles que sejam úteis ao modelo. Atributos irrelevantes podem causar efeito negativo em um modelo. Atributos correlacionados podem deixar os coeficientes de uma regressão (ou a importância de atributos em uma árvore) instáveis ou difíceis de interpretar”. (HARRISON, M., 2020, p. 88)
Além de identificar os atributos relevantes e não correlacionados, não podemos esquecer a “maldição da dimensionalidade”, porque a medida que a dimensão de dados aumenta, mais esparsos ficam os dados, o que gera a dificuldade de encontrar um “sinal” e cálculos de “vizinhança”, gerando a necessidade de coletar mais dados.
Observando o Princípio da Navalha de Occam, se temos que escolher entre dois modelos, que representam o mesmo fenômeno, a preferência é para o mais simples. A razão dessa escolha é bem direta: porque o modelo mais simples vai generalizar melhor.
Para tornar a aprendizagem mais simples em Machine Learning, o conjunto de dados mais simples, depende da quantidade de colunas. E para tornar o conjunto de dados mais simples, podemos identificar as colunas que são Colineares, ou seja, variáveis que explicam a mesma coisa e removê-las, não utilizando-as para o treinamento do modelo. Segue abaixo, alguns tipos de seleção de variáveis.
Tipos de seleção de variáveis: mecanismo, vantagens e desvantagens
a) Seleção Univariada (Filter Methods)
O objetivo da seleção univariada é classificar quais são as variáveis relevantes ou não para o modelo. A relevância é extraída a partir da explicação do fenômeno, ou seja, a feature que melhor explica a variável resposta.
Nesse método, a relevância pode ser explicada pelo Coeficiente de Correlação, que possui um range de -1 a 1. Quanto mais próximo de 1 e -1, mais relevante é a feature.
Esse método tem como vantagens ser simples, rápido e fácil de entender. No entanto, não considera a influência entre as variáveis.
Abaixo, segue um quadro explicativo para escolher o método de correlação de acordo com o tipo de variável:

b) Seleção por importância (Embedded Methods)
É conhecido carinhosamente como método embutido, porque o método de seleção é um subproduto do próprio sistema de aprendizado de um sistema e utiliza a importância como critério de escolha da variável .
Por exemplo, o RandomForest é um algoritmo que funciona bem para fazer previsões em problemas de classificação e para ter alta acurácia precisa das melhores features, então essa seleção por importância já está embutida no processo. Esse algoritmo já utiliza a seleção das variáveis por importância encontrar e selecionar as features, para construir o seu aprendizado.
O Random Forest, Lasso Regression e Ridge Regression são algoritmos que se comportam dessa forma.
A regressão é uma soma ponderada, cada coluna explica um pouco do fenômeno, então a regressão dá um peso para cada uma das variáveis. Variáveis com peso alto são importantes para o aprendizado do modelo. Os pesos demonstram a importância da variáveis. O Lasso e o Ridge utilizam esse sistema.
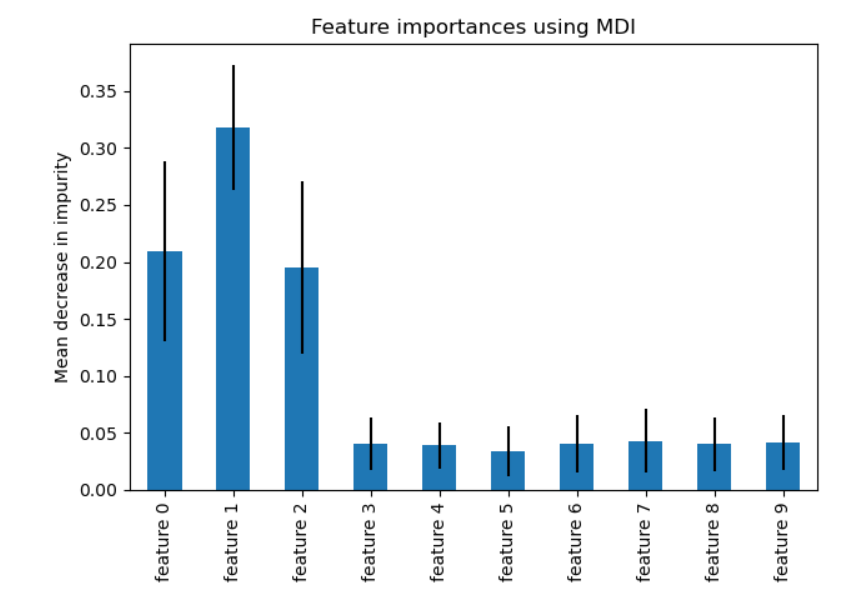
a) Random Forest (Giny Impurity): Este algoritmo seleciona as variáveis e divide o conjunto de dados original, criando dois grupos mais similares possíveis(homogêneos entre si). A variável que separa esses dois conjuntos similares é uma variável importante.
O resultado que trás a importância das features pode ser plotado em um gráfico, mostrando o percentual de importância. Observa-se que no gráfico abaixo, as features 0, 1 e 2 explicam em torno de 70% do fenômeno:
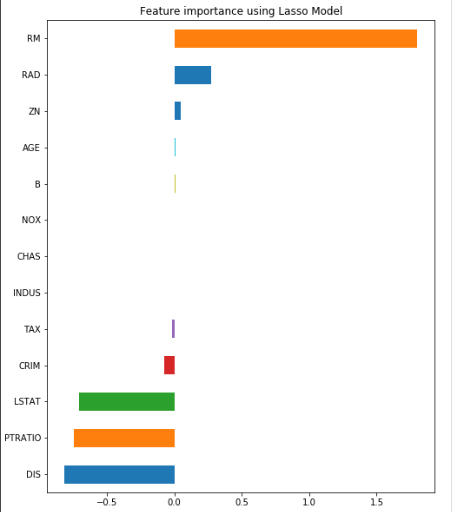
b) Lasso Regression: Funciona a partir da divisão das variáveis em pesos positivos e negativos. Seleciona-se as variáveis como importantes, quando apresentam os maiores pesos positivos e negativos. É possível definir o parâmetro alpha, que atua como um parâmetro de regularização (se o valor de alpha aumenta, menor peso será dados aos atributos que são menos importantes). Como exemplo, no gráfico abaixo, as features Nox, Chas e Indus, não são importantes:
c) Seleção por Subset (Wrapper Methods)
A seleção de variáveis por Subset, pode ser explicada em uma sequência de passos e o objetivo do processo é determinar a importância das variáveis. Os passos podem ser resumidos da seguinte forma:
- Seleção uma única variável (aleatoriamente) + variável resposta
- Treinamento do modelo de ML com essas duas variáveis
- Cálculo da performance do modelo (acurácia e/ou erro)
- Observação se a performance aumentou. Se aumentou, continua o processo
- Adição de mais uma variável aleatoriamente (agora são duas variáveis + variável resposta): retreino, recalculo da acurácia/erro e observação se a performance aumentou. Se aumentou, mantém essa variável e o processo continua igual para o restante das variáveis (ou seja, mantém as que estão funcionando bem e acrescenta mais uma). Quando a acurácia não aumentar, remove-se a variável e volta para o fluxo.
- Como resultado, o dataset final é menor e contém apenas as variáveis classificadas como importantes. Existem algoritmos que fazem essa sequencia de passos, identificando e trazendo as features mais importantes, por exemplo o Boruta.
O funcionamento do Boruta
O algoritmo Boruta, seleciona duas variáveis aleatoriamente do dataset original e cria duas variáveis shadow (cópia da variável original com as linhas “embaralhadas”). As linhas são misturadas para retirar a correlação entre elas.
Com esse novo conjunto de dados (4 variáveis), o modelo é treinado (normalmente com o Random Forest) e encontra a importância das 4 variáveis. O Boruta seleciona a variável shadow mais importante e compara todas as variáveis originais com ela.
E, organiza uma tabela, chamada Sucess Count (contagem de sucesso), se a variável original tiver uma importância maior que a importância da variável Shadow coloca-se 1, senão coloca zero.
Sobre a tabela Sucess Count, é possível construir uma distribuição binomial, traçando um “limite” e, a partir do cálculo do p-value de cada variável original saber se a variável é ou não importante: se o p-value da variável for menor que o p-value limite, a variável é considerada importante, ao contrário, rejeita essa variável. No final, o dataset é reduzido, apenas com as variáveis importantes.
Nota: O p-value ajuda a definir se uma hipótese é verdadeira ou se deve ser rejeitada.
|
1 2 3 4 5 6 7 8 9 10 |
# Import from boruta import BorutaPy from sklearn.ensemble import RandomForestRegressor # Implementação do Boruta boruta=BorutaPy(rf, n_estimators='auto', verbose=2, random_state=42).fit(X_train_n, y_train_n) # Trazendo as features importantes e selecionadas pelo Boruta em forma de lista cols_selected = boruta.support_.tolist() cols_selected_boruta = X_train.iloc[:,cols_selected].columns.to_list() |
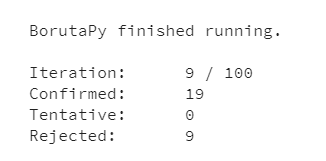
Iteration: nº de iterações (110 é o nº máximo de iterações)
Confirmed: nº de variáveis escolhidas como relevantes
Tentativas: variáveis “duvidosas”, que não podem ser descartadas ou confirmadas
Rejected: nº de variáveis confirmadas
Neste post tratamos sobre a importância de encontrar as features relevantes para melhorar a performance do modelo de Machine Learning e como a dimensionalidade do conjunto de dados pode afetar esse desempenho. E, para concluir, gostaria de deixar como sugestão de leitura, o capítulo 8, do livro Machine Learning: Trabalhando com dados estruturados em Python, que aborda algumas das técnicas aqui discutidas.
Em um próximo post, vamos discutir essa seleção de importância de atributos sob a perspectiva dos modelos baseados em árvores.
Obrigada pelo seu tempo de leitura.
Meus contatos:
github.com/denisemerazzi
www.linkedin.com/in/denisewmerazzi/