Nesse artigo, você vai conhecer os principais conceitos e comandos para utilizar a ferramenta Git nos seus projetos de Data Science, desde a criação de um novo repositório local até os conceitos mais avançados como branchs e merge, que facilitam o trabalho em equipe em um ambiente remoto e colaborativo.
O que é e para que serve?
O Git é uma ferramenta que não pode faltar na formação de um Cientista de Dados, porque permite o controle de versionamento de códigos, organiza as alterações realizadas ao longo do projeto, permite fazer um push e um pull dessas alterações e continuar o desenvolvimento do projeto, com as suas melhorias implementadas.
O ideia do Git é fornecer um repositório local para armazenar o projeto, que pode funcionar offline para um trabalho mais individual e além disso facilita o compartilhamento das alterações do projeto para um trabalho em equipe, organizado em ambiente remoto.
O Git apresenta muitas facilidades que o tornam uma ferramenta indispensável:
- Segurança e facilidade no controle de versões do Projeto.
- Construção de branches, que são ambientes seguros para desenvolver e testar, sem impactar no que já está em produção funcionando.
- É possível ignorar alguns arquivos, através da utilização do .gitignore, para filtrar os arquivos que não fazem parte do código-fonte do projeto.
- Operações rápidas e fáceis.
- Capacidade para adicionar ou mover arquivos.
- É possível entender o histórico das modificações realizadas.
Conhecendo a área de trabalho do Git
- Staging: onde ficam todos os arquivos alterados e que foram marcados como prontos para terem o seu estado salvo, com um commit. Utilizamos o comando git add <nome_arquivo> para enviar um arquivo para a Staging Area.
- Repository: área onde ficam todos os arquivos versionados pelo Git, que foram salvos com o comando git commit.
- Working Directory: área onde ficam todos os arquivos que foram alterados (saíram da área Repository), mas ainda não foram marcados como prontos para serem commitados. Utiliza-se o comando git restore<nome_arquivo> para remover o arquivo de dentro da Working Directory e retornar ao último estado salvo no Repository (a funcionalidade deste comando é desfazer as alterações e voltar para o Repository ).
Alguns comandos essenciais no Git que você não pode deixar de conhecer
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# Inicializar o repositório. $ git init # Visualizar a situação do repositório local. $ git status # Adicionar um novo arquivo. $ git add <nome_arquivo> # Adicionar de uma única vez todos os arquivos. $ git add. # Salvar um novo arquivo. $ git commit -m “Mensagem_commit” |
Comandos para a visualização do histórico e alteração de commits
|
1 2 3 4 5 6 7 8 9 |
# Exibir os commits. $ git log # Visualizar em forma de lista o histórico de commits. # Verificar as informações essenciais em uma única linha. $ git log --oneline # Alterar e substituir o último commit. $ git commit -m "mensagem" --amend |
Comandos para alteração de commits anteriores
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
# Mostrar quais alterações foram feitas. # Verificar a diferença entre dois commits. $ git diff # Verificar do head até n commits anteriores. # Verificar quais alterações foram feitas. $ git log -p -<nº de commits anteriores> # Estruturar ou reescrever o histórico de commits. # Possui um modo interativo de inserção <i>. # <i> facilita a reescrita do commit. $ git rebase -i HEAD ~<n> # Ajustar a mensagem do commit. $ git rebase reword # Ajustar a mensagem a partir de grupos de commits $ git rebase squash # Voltar até o estado original do HEAD no repositório local. # Permite salvar e observar as alterações que queremos fazer. $ git reset --mixed <commit> # Apagar tudo e voltar para o estado anterior. $ git reset --hard <commit> |
Comandos de recuperação de arquivos deletados
|
1 2 3 4 5 6 |
# Recuperar um arquivo excluído, porém não commitado. $ git restore <arquivo> # ou $ git reset -- mixed <commit> # e então $ git restore <arquivo> |
Comandos para trabalhar em equipe em um ambiente remoto – GitHub
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# Adicionar um novo repositório remoto. $ git remote add <nome_repos> <url_github> # Remover o repositório. $ git remote remove <nome_repos> # Verificar repositórios remotos que estão no repositório local. $ git remote -v # Baixar um projeto do repositório remoto para a máquina local. $ git clone <url> # Enviar as atualizações para um repositório remoto. $ git push # Receber as atualizações de um repositório remoto. $ git pull |
Trabalhando com Branchs
A branch permite modificar os códigos de um projeto, sem alterar o que já está funcionando, promovendo a independência no desenvolvimento para testar e alterar antes de enviar para o ambiente de produção. Assim, a equipe pode produzir de forma independente, com mais segurança no projeto, minimizando os conflitos de merge.
Comandos para criar e mover Branchs
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
# Criar uma branch e mover o ponteiro HEAD direto pra ela. $ git checkout -b <nome> # Criar uma branch nova a partir de outra branch. $ git branch <nome> # Movimentar o HEAD de uma branch para a outra. # Permite linhas em desenvolvimento de forma independente. $ git checkout <nome> # Mover o HEAD para uma branch específica. $ git checkout <SHA-1> # Enviar uma branch local para o repositório remoto. $ git push - u <nome_repos_remoto><nome_branch> # Enviar várias branchs para o repositório remoto. $ git push --all # Mostrar todas as branchs do repositório remoto. $ git branch -a # Apagar uma branch: # Fazer dois commits (um local e um remoto): # a) Branch local: $ git branch -d <nome_branch_local) # b) Remoto: $ git push --delete origin <nome_branch> |
Realização do merge
O merge é a união de commits e é muito utilizado quando trabalha-se com branch.
O Git não consegue resolver automaticamente quando ocorre o conflito de merge, ou seja, alterações no mesmo arquivo e/ou linhas de código.
Esses conflitos podem acontecer tanto na união entre branchs quanto entre commits.
|
1 |
$ git merge |
Para utilizar o comando git merge, tem-se que estar na branch que irá receber as alterações.
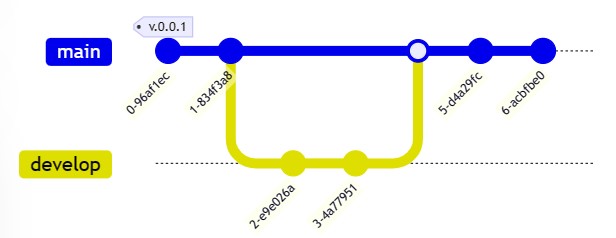
No Diagrama abaixo, observa-se que os dois primeiros commits são feitos na Branch main. Quando a Branch develop for criada, uma cópia do projeto será adicionada à ela. E, esta versão do projeto, após suas alterações, retorna através de um merge para a Branch main, atualizando a sua versão.
Comandos para identificar o conflito de merge dentro do Jupyter Notebook
O Jupyter Notebook é “por baixo dos panos” um arquivo json, o que dificulta bastante na hora de identificar onde está acontecendo o problema.
Para visualizar o arquivo fonte, dentro do Jupyter Notebook e identificar onde aconteceu o conflito de merge, utiliza-se o
Reopen Editor With -> text editor.
Quando ocorre o erro no merge no Jupyter, é mais assertivo desfazer o processo. E para auxiliar na identificação do problema, é possível utilizar o pacote nbdime.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# Abortar o processo. $ git merge --abort # Pacote nbdime # a) Carregar as variáveis de ambiente: $ conda env list # b) Ativar: $ conda activate (caminho da variável de ambiente) # c) Instalar o pacote nbdime: $ pip install -u nbdime (-u instala a versão mais recente) # Visualizar o conteúdo de cada branch. $ git -nbmergedriver config --enable |
Agora, você é capaz de utilizar a ferramenta Git para desenvolver os seus projetos em Data Science, otimizando o versionamento de códigos de maneira segura, eficiente e organizada.
Se você ficou com alguma dúvida sobre algum conceito importante como branch e head, pode visitar um pequeno post que elaborei no formato de um glossário, trazendo o significado de algumas palavras-chave dentro do Git. Pode ser encontrado neste link:
Finalizando, agradeço o seu tempo dedicado à leitura deste artigo, espero ter contribuído de alguma forma e nos encontramos novamente na leitura de futuros artigos.
Conceitos essenciais no Git – My Blog (merazzi.com.br)
Meus contatos:
github.com/denisemerazzi
www.linkedin.com/in/denisewmerazzi/